文章詳情頁
python - 怎么用爬蟲批量抓取網頁中的圖片?
瀏覽:106日期:2022-06-27 11:03:37
問題描述
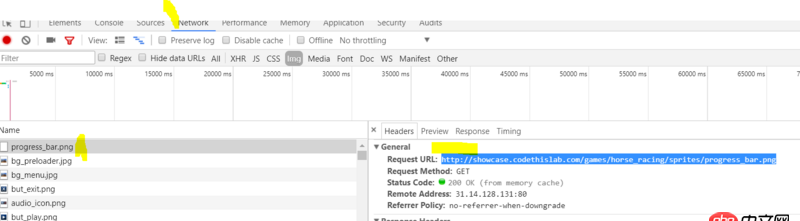
如圖,通過network查看加載圖片,要一張一張右鍵保存很麻煩,有沒有辦法寫個爬蟲批量抓取這里的圖片》?
問題解答
回答1:這個需求, 如果你會爬蟲其實很簡單, 不外乎幾個步驟:
首頁或者有圖片的頁面, 通過正則或者其他框架, 獲取圖片的url
通過requests庫或者urllib庫, 訪問上面圖片url的地址
以二進制的形式, 寫入本地硬盤
參考代碼:
import re, requestsr = requests.get('http://...頁面地址..')p = re.compile(r’相應的正則表達式匹配’)image = p.findall(r.text)[0] # 通過正則獲取所有圖片的urlir = requests.get(image) # 訪問圖片的地址sz = open(’logo.jpg’, ’wb’).write(ir.content) # 將其內容寫入本地print(’logo.jpg’, sz,’bytes’)
更多詳情, 可以參考學習requests官方文檔: requests文檔
回答2:可以的,爬蟲五個部分:調度程序url去重下載器網頁解析數據存儲對于下載圖片的思路是:獲取圖片所在網頁內容,解析img標簽,得到圖片地址,然后便利圖片網址,下載每張圖片,將下載過的圖片地址保存在布隆過濾器中,避免重復下載,每次下載一張圖片時,通過網址檢查是否下載過,當圖片下載到本地后,可以將圖片路徑保存在數據庫中,圖片文件保存在文件夾中,或者直接將圖片保存在數據庫中。python使用request+beautifulsoup4java使用jsoup
回答3:如果多個網站或者一個網站需要爬到很深的情況下,樓上的方式直接遞歸或者深度遍歷就OK
相關文章:
1. mysql 為什么主鍵 id 和 pid 都市索引, id > 10 走索引 time > 10 不走索引?2. css3 - 純css實現點擊特效3. javascript - Img.complete和img.onload判斷圖片加載完成有什么區別?4. java中返回一個對象,和輸出對像的值,意義在哪兒5. mysql - 在不允許改動數據表的情況下,如何優化以varchar格式存儲的時間的比較?6. docker網絡端口映射,沒有方便點的操作方法么?7. javascript - 有適合開發手機端Html5網頁小游戲的前端框架嗎?8. 推薦好用mysql管理工具?for mac和pc9. css - 網頁div區塊 像蘋果一樣可左右滑動 手機與電腦10. javascript - 關于apply()與call()的問題
排行榜
 網公網安備
網公網安備