Python爬蟲基礎(chǔ)之初次使用scrapy爬蟲實例
在專門供爬蟲初學(xué)者訓(xùn)練爬蟲技術(shù)的網(wǎng)站(http://quotes.toscrape.com)上爬取名言警句。
創(chuàng)建項目在開始爬取之前,必須創(chuàng)建一個新的Scrapy項目。進(jìn)入您打算存儲代碼的目錄中,運行下列命令:
(base) λ scrapy startproject quotesNew scrapy project ’quotes ’, using template directory ’d: anaconda3libsite-packagesscrapytemp1atesproject ’, created in: D:XXXYou can start your first spider with : cd quotes scrapy genspider example example. com
首先切換到新建的爬蟲項目目錄下,也就是/quotes目錄下。然后執(zhí)行創(chuàng)建爬蟲文件的命令:
D:XXX(master)(base) λ cd quotes D:XXXquotes (master)(base) λ scrapy genspider quotes quotes.comcannot create a spider with the same name as your project D :XXXquotes (master)(base) λ scrapy genspider quote quotes.comcreated spider ’quote’ using template ’basic’ in module:quotes.spiders.quote
該命令將會創(chuàng)建包含下列內(nèi)容的quotes目錄:

robots協(xié)議也叫robots.txt(統(tǒng)一小寫)是一種存放于網(wǎng)站根目錄下的ASCII編碼的文本文件,它通常告訴網(wǎng)絡(luò)搜索引擎的網(wǎng)絡(luò)蜘蛛,此網(wǎng)站中的哪些內(nèi)容是不應(yīng)被搜索引擎的爬蟲獲取的,哪些是可以被爬蟲獲取的。
robots協(xié)議并不是一個規(guī)范,而只是約定俗成的。
#filename : settings.py#obey robots.txt rulesROBOTSTXT__OBEY = False分析頁面
編寫爬蟲程序之前,首先需要對待爬取的頁面進(jìn)行分析,主流的瀏覽器中都帶有分析頁面的工具或插件,這里我們選用Chrome瀏覽器的開發(fā)者工具(Tools→Developer tools)分析頁面。
數(shù)據(jù)信息在Chrome瀏覽器中打開頁面http://lquotes.toscrape.com,然后選擇'Elements',查看其HTML代碼。
可以看到每一個標(biāo)簽都包裹在
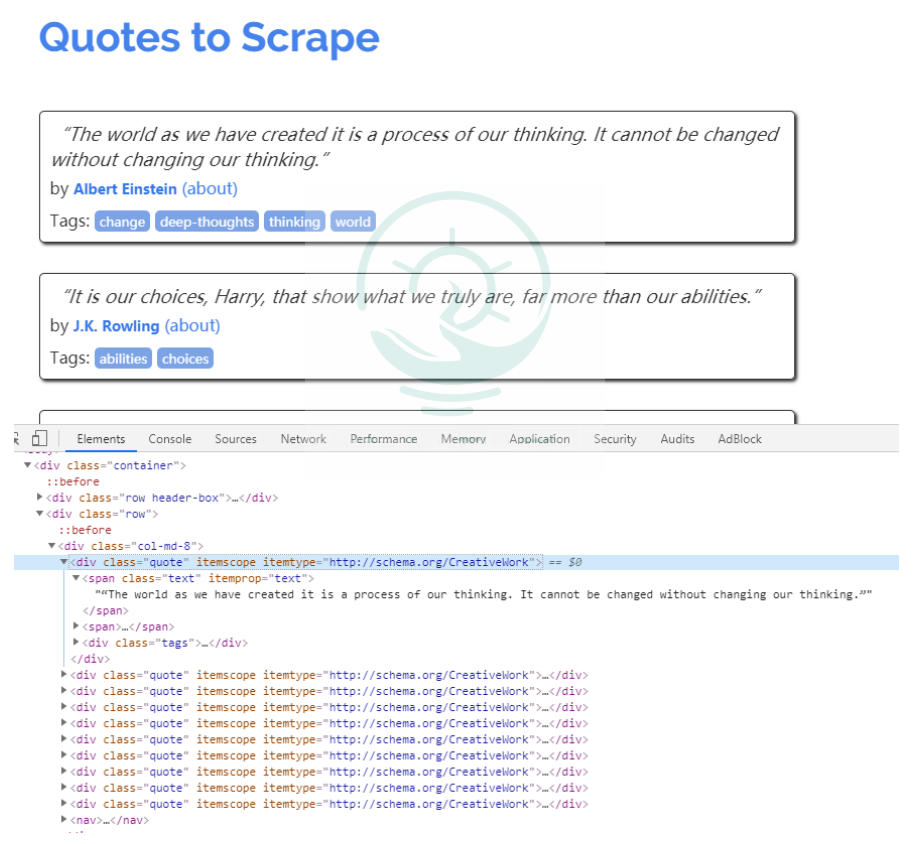
分析完頁面后,接下來編寫爬蟲。在Scrapy中編寫一個爬蟲, 在scrapy.Spider中編寫代碼Spider是用戶編寫用于從單個網(wǎng)站(或者-些網(wǎng)站)爬取數(shù)據(jù)的類。
其包含了-個用于下載的初始URL,如何跟進(jìn)網(wǎng)頁中的鏈接以及如何分析頁面中的內(nèi)容,提取生成item的方法。
為了創(chuàng)建一個Spider, 您必須繼承scrapy.Spider類,且定義以下三個屬性:
name:用于區(qū)別Spider。該名字必須是唯一-的, 您不可以為不同的Spider設(shè)定相同的名字。 start _urls:包含了Spider在啟動時進(jìn)行爬取的ur列表。因此, 第一個被獲取到的頁面將是其中之一。后續(xù)的URL則從初始的URL獲取到的數(shù)據(jù)中提取。 parse():是spider的一一個方法。被調(diào)用時,每個初始URL完成下載后生成的Response對象將會作為唯一的參數(shù)傳遞給該函數(shù)。該方法負(fù)責(zé)解析返回的數(shù)據(jù)(response data),提取數(shù)據(jù)(生成item)以及生成需要進(jìn)一步處理的URL 的Request對象。import scrapy class QuoteSpi der(scrapy . Spider): name =’quote’ allowed_ domains = [’ quotes. com ’] start_ urls = [’http://quotes . toscrape . com/’]def parse(self, response) :pass
下面對quote的實現(xiàn)做簡單說明。
scrapy.spider :爬蟲基類,每個其他的spider必須繼承自該類(包括Scrapy自帶的其他spider以及您自己編寫的spider)。 name是爬蟲的名字,是在genspider的時候指定的。 allowed_domains是爬蟲能抓取的域名,爬蟲只能在這個域名下抓取網(wǎng)頁,可以不寫。 start_ur1s是Scrapy抓取的網(wǎng)站,是可迭代類型,當(dāng)然如果有多個網(wǎng)頁,列表中寫入多個網(wǎng)址即可,常用列表推導(dǎo)式的形式。 parse稱為回調(diào)函數(shù),該方法中的response就是start_urls 網(wǎng)址發(fā)出請求后得到的響應(yīng)。當(dāng)然也可以指定其他函數(shù)來接收響應(yīng)。一個頁面解析函數(shù)通常需要完成以下兩個任務(wù):1.提取頁面中的數(shù)據(jù)(re、XPath、CSS選擇器)2.提取頁面中的鏈接,并產(chǎn)生對鏈接頁面的下載請求。頁面解析函數(shù)通常被實現(xiàn)成一個生成器函數(shù),每一項從頁面中提取的數(shù)據(jù)以及每一個對鏈接頁面的下載請求都由yield語句提交給Scrapy引擎。
解析數(shù)據(jù)import scrapy def parse(se1f,response) : quotes = response.css(’.quote ’) for quote in quotes:text = quote.css( ’.text: :text ’ ).extract_first()auth = quote.css( ’.author : :text ’ ).extract_first()tages = quote.css(’.tags a: :text’ ).extract()yield dict(text=text,auth=auth,tages=tages)
重點:
response.css(直接使用css語法即可提取響應(yīng)中的數(shù)據(jù)。 start_ur1s 中可以寫多個網(wǎng)址,以列表格式分割開即可。 extract()是提取css對象中的數(shù)據(jù),提取出來以后是列表,否則是個對象。并且對于 extract_first()是提取第一個運行爬蟲在/quotes目錄下運行scrapycrawlquotes即可運行爬蟲項目。運行爬蟲之后發(fā)生了什么?
Scrapy為Spider的start_urls屬性中的每個URL創(chuàng)建了scrapy.Request對象,并將parse方法作為回調(diào)函數(shù)(callback)賦值給了Request。
Request對象經(jīng)過調(diào)度,執(zhí)行生成scrapy.http.Response對象并送回給spider parse()方法進(jìn)行處理。
完成代碼后,運行爬蟲爬取數(shù)據(jù),在shell中執(zhí)行scrapy crawl <SPIDER_NAME>命令運行爬蟲’quote’,并將爬取的數(shù)據(jù)存儲到csv文件中:
(base) λ scrapy craw1 quote -o quotes.csv2021-06-19 20:48:44 [scrapy.utils.log] INF0: Scrapy 1.8.0 started (bot: quotes)
等待爬蟲運行結(jié)束后,就會在當(dāng)前目錄下生成一個quotes.csv的文件,里面的數(shù)據(jù)已csv格式存放。
-o支持保存為多種格式。保存方式也非常簡單,只要給上文件的后綴名就可以了。(csv、json、pickle等)
到此這篇關(guān)于Python爬蟲基礎(chǔ)之初次使用scrapy爬蟲實例的文章就介紹到這了,更多相關(guān)Python scrapy框架內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. XML入門精解之結(jié)構(gòu)與語法2. 利用CSS3新特性創(chuàng)建透明邊框三角3. XML解析錯誤:未組織好 的解決辦法4. XML入門的常見問題(二)5. CSS3實例分享之多重背景的實現(xiàn)(Multiple backgrounds)6. HTML5 Canvas繪制圖形從入門到精通7. CSS Hack大全-教你如何區(qū)分出IE6-IE10、FireFox、Chrome、Opera8. 概述IE和SQL2k開發(fā)一個XML聊天程序9. HTML DOM setInterval和clearInterval方法案例詳解10. XML入門的常見問題(一)
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備