Java org.w3c.dom.Document 類方法引用報(bào)錯(cuò)
The method setXmlVersion(String) is undefined for the type Document
開發(fā)時(shí)我們可能會(huì)碰到這樣的問(wèn)題,它產(chǎn)生的原因是我們實(shí)際需要調(diào)用的是 JDK 環(huán)境 rt.jar 下的 org.w3c.dom.org.w3c.dom.Document ,但事實(shí)上 Eclipse 等 IDE 工具此時(shí)自動(dòng)為我們調(diào)用的是 J2EE 中的 xercesxmlParserAPIs2.6.2xmlParserAPIs-2.6.2.jar ,這一點(diǎn)通過(guò) Ctrl 左鍵點(diǎn)擊 Document 類可以發(fā)現(xiàn)。
發(fā)現(xiàn)問(wèn)題出在哪里就好解決了
我們需要做的是調(diào)整 Eclipse 的調(diào)用順序項(xiàng)目右鍵 > Properties > Java Build Path > 右邊 Order and Export
把 JRE System Library 通過(guò)點(diǎn)擊 Up 按鈕放到 J2EE(Maven Dependencies) 的上面即可。
org.w3c.dom(java dom)解析XML文檔位于org.w3c.dom操作XML會(huì)比較簡(jiǎn)單,就是將XML看做是一顆樹,DOM就是對(duì)這顆樹的一個(gè)數(shù)據(jù)結(jié)構(gòu)的描述,但對(duì)大型XML文件效果可能會(huì)不理想
首先來(lái)了解點(diǎn)Java DOM 的 API:1.解析器工廠類:DocumentBuilderFactory
創(chuàng)建的方法:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
2.解析器:DocumentBuilder
創(chuàng)建方法:通過(guò)解析器工廠類來(lái)獲得
DocumentBuilder db = dbf.newDocumentBuilder();
3.文檔樹模型Document
創(chuàng)建方法:a.通過(guò)xml文檔 Document doc = db.parse('bean.xml'); b.將需要解析的xml文檔轉(zhuǎn)化為輸入流 InputStream is = new FileInputStream('bean.xml');
Document doc = db.parse(is);
Document對(duì)象代表了一個(gè)XML文檔的模型樹,所有的其他Node都以一定的順序包含在Document對(duì)象之內(nèi),排列成一個(gè)樹狀結(jié)構(gòu),以后對(duì)XML文檔的所有操作都與解析器無(wú)關(guān),
直接在這個(gè)Document對(duì)象上進(jìn)行操作即可;
包含的方法:


4.節(jié)點(diǎn)列表類NodeList
NodeList代表了一個(gè)包含一個(gè)或者多個(gè)Node的列表,根據(jù)操作可以將其簡(jiǎn)化的看做為數(shù)組
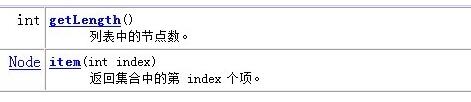
5.節(jié)點(diǎn)類Node
Node對(duì)象是DOM中最基本的對(duì)象,代表了文檔樹中的抽象節(jié)點(diǎn)。但在實(shí)際使用中很少會(huì)直接使用Node對(duì)象,而是使用Node對(duì)象的子對(duì)象Element,Attr,Text等
6.元素類Element
是Node類最主要的子對(duì)象,在元素中可以包含屬性,因而Element中有存取其屬性的方法

7.屬性類Attr
代表某個(gè)元素的屬性,雖然Attr繼承自Node接口,但因?yàn)锳ttr是包含在Element中的,但并不能將其看做是Element的子對(duì)象,因?yàn)锳ttr并不是DOM樹的一部分
基本的知識(shí)就到此結(jié)束,更加具體的大家可以參閱JDK API文檔
實(shí)戰(zhàn):1.使用DOM來(lái)遍歷XML文檔中的全部?jī)?nèi)容并且插入元素:
school.xml文檔:
<?xml version = '1.0' encoding = 'utf-8'?><School> <Student><Name>沈浪</Name><Num>1006010022</Num><Classes>信管2</Classes><Address>浙江杭州3</Address><Tel>123456</Tel> </Student> <Student><Name>沈1</Name><Num>1006010033</Num><Classes>信管1</Classes><Address>浙江杭州4</Address><Tel>234567</Tel> </Student> <Student><Name>沈2</Name><Num>1006010044</Num><Classes>生工2</Classes><Address>浙江杭州1</Address><Tel>345678</Tel> </Student> <Student><Name>沈3</Name><Num>1006010055</Num><Classes>電子2</Classes><Address>浙江杭州2</Address><Tel>456789</Tel> </Student></School>
DomDemo.java
package xidian.sl.dom;import java.io.FileOutputStream;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import org.apache.crimson.tree.XmlDocument;import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.NodeList;public class DomDemo { /** * 遍歷xml文檔 * */ public static void queryXml(){try{ //得到DOM解析器的工廠實(shí)例 DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); //從DOM工廠中獲得DOM解析器 DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder(); //把要解析的xml文檔讀入DOM解析器 Document doc = dbBuilder.parse('src/xidian/sl/dom/school.xml'); System.out.println('處理該文檔的DomImplementation對(duì)象 = '+ doc.getImplementation()); //得到文檔名稱為Student的元素的節(jié)點(diǎn)列表 NodeList nList = doc.getElementsByTagName('Student'); //遍歷該集合,顯示結(jié)合中的元素及其子元素的名字 for(int i = 0; i< nList.getLength() ; i ++){Element node = (Element)nList.item(i);System.out.println('Name: '+ node.getElementsByTagName('Name').item(0).getFirstChild().getNodeValue());System.out.println('Num: '+ node.getElementsByTagName('Num').item(0).getFirstChild().getNodeValue());System.out.println('Classes: '+ node.getElementsByTagName('Classes').item(0).getFirstChild().getNodeValue());System.out.println('Address: '+ node.getElementsByTagName('Address').item(0).getFirstChild().getNodeValue());System.out.println('Tel: '+ node.getElementsByTagName('Tel').item(0).getFirstChild().getNodeValue()); } }catch (Exception e) { // TODO: handle exception e.printStackTrace();} } /** * 向已存在的xml文件中插入元素 * */ public static void insertXml(){Element school = null;Element student = null;Element name = null;Element num = null;Element classes = null;Element address = null;Element tel = null;try{ //得到DOM解析器的工廠實(shí)例 DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); //從DOM工廠中獲得DOM解析器 DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder(); //把要解析的xml文檔讀入DOM解析器 Document doc = dbBuilder.parse('src/xidian/sl/dom/school.xml'); //得到文檔名稱為Student的元素的節(jié)點(diǎn)列表 NodeList nList = doc.getElementsByTagName('School'); school = (Element)nList.item(0); //創(chuàng)建名稱為Student的元素 student = doc.createElement('Student'); //設(shè)置元素Student的屬性值為231 student.setAttribute('examId', '23'); //創(chuàng)建名稱為Name的元素 name = doc.createElement('Name'); //創(chuàng)建名稱為 香香 的文本節(jié)點(diǎn)并作為子節(jié)點(diǎn)添加到name元素中 name.appendChild(doc.createTextNode('香香')); //將name子元素添加到student中 student.appendChild(name); /** * 下面的元素依次加入即可 * */ num = doc.createElement('Num'); num.appendChild(doc.createTextNode('1006010066')); student.appendChild(num);classes = doc.createElement('Classes'); classes.appendChild(doc.createTextNode('眼視光5')); student.appendChild(classes);address = doc.createElement('Address'); address.appendChild(doc.createTextNode('浙江溫州')); student.appendChild(address);tel = doc.createElement('Tel'); tel.appendChild(doc.createTextNode('123890')); student.appendChild(tel);//將student作為子元素添加到樹的根節(jié)點(diǎn)school school.appendChild(student); //將內(nèi)存中的文檔通過(guò)文件流生成insertSchool.xml,XmlDocument位于crison.jar下 ((XmlDocument)doc).write(new FileOutputStream('src/xidian/sl/dom/insertSchool.xml')); System.out.println('成功');}catch (Exception e) { // TODO: handle exception e.printStackTrace();}} public static void main(String[] args){//讀取DomDemo.queryXml();//插入DomDemo.insertXml(); }}
運(yùn)行后結(jié)果:

然后到目錄下查看生成的xml文件:

打開查看內(nèi)容:
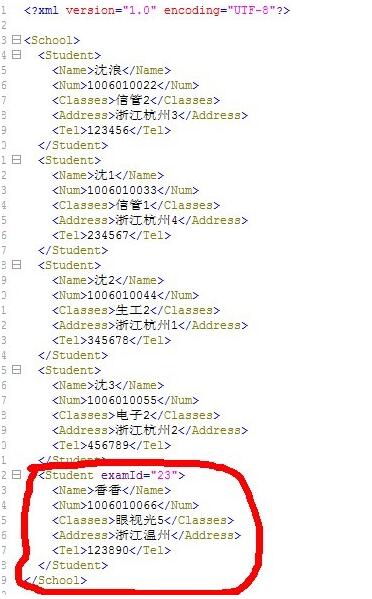
上面添加元素后輸出的文件與之前的文件不是同一個(gè)文件,如果需要輸出到原文件中,那么只要將路徑改為原文間路徑即可:src/xidian/sl/dom/school.xml
2.創(chuàng)建XML過(guò)程與插入過(guò)程相似,就是Document需要?jiǎng)?chuàng)建
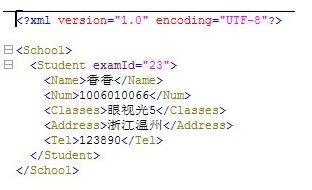
package xidian.sl.dom;import java.io.FileOutputStream;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import org.apache.crimson.tree.XmlDocument;import org.w3c.dom.Document;import org.w3c.dom.Element;public class CreateNewDom { /** * 創(chuàng)建xml文檔 * */ public static void createDom(){Document doc;Element school,student;Element name = null;Element num = null;Element classes = null;Element address = null;Element tel = null;try{ //得到DOM解析器的工廠實(shí)例 DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); //從DOM工廠中獲得DOM解析器 DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder(); //創(chuàng)建文檔樹模型對(duì)象 doc = dbBuilder.newDocument(); if(doc != null){//創(chuàng)建school元素school = doc.createElement('School');//創(chuàng)建student元素student = doc.createElement('Student');//設(shè)置元素Student的屬性值為231student.setAttribute('examId', '23');//創(chuàng)建名稱為Name的元素name = doc.createElement('Name');//創(chuàng)建名稱為 香香 的文本節(jié)點(diǎn)并作為子節(jié)點(diǎn)添加到name元素中name.appendChild(doc.createTextNode('香香'));//將name子元素添加到student中student.appendChild(name);/** * 下面的元素依次加入即可 * */num = doc.createElement('Num');num.appendChild(doc.createTextNode('1006010066'));student.appendChild(num);classes = doc.createElement('Classes');classes.appendChild(doc.createTextNode('眼視光5'));student.appendChild(classes);address = doc.createElement('Address');address.appendChild(doc.createTextNode('浙江溫州'));student.appendChild(address);tel = doc.createElement('Tel');tel.appendChild(doc.createTextNode('123890'));student.appendChild(tel);//將student作為子元素添加到樹的根節(jié)點(diǎn)schoolschool.appendChild(student);//添加到文檔樹中doc.appendChild(school);//將內(nèi)存中的文檔通過(guò)文件流生成insertSchool.xml,XmlDocument位于crison.jar下((XmlDocument)doc).write(new FileOutputStream('src/xidian/sl/dom/createSchool.xml'));System.out.println('創(chuàng)建成功'); }}catch (Exception e) { // TODO: handle exception e.printStackTrace();} } public static void main(String[] args) {CreateNewDom.createDom(); }}
運(yùn)行結(jié)果:
DOM的操作應(yīng)該還是非常簡(jiǎn)單明了的,掌握了沒哦。
以上為個(gè)人經(jīng)驗(yàn),希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. 存儲(chǔ)于xml中需要的HTML轉(zhuǎn)義代碼2. XML入門的常見問(wèn)題(一)3. ASP實(shí)現(xiàn)加法驗(yàn)證碼4. ASP中if語(yǔ)句、select 、while循環(huán)的使用方法5. ASP.NET MVC使用異步Action的方法6. 匹配模式 - XSL教程 - 47. ASP.NET MVC通過(guò)勾選checkbox更改select的內(nèi)容8. JS中map和parseInt的用法詳解9. XML入門精解之結(jié)構(gòu)與語(yǔ)法10. CSS Hack大全-教你如何區(qū)分出IE6-IE10、FireFox、Chrome、Opera

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備