文章詳情頁
Python爬蟲程序架構和運行流程原理解析
瀏覽:3日期:2022-08-03 10:24:51
1 前言
Python開發網絡爬蟲獲取網頁數據的基本流程為:
發起請求
通過URL向服務器發起request請求,請求可以包含額外的header信息。
獲取響應內容
服務器正常響應,將會收到一個response,即為所請求的網頁內容,或許包含HTML,Json字符串或者二進制的數據(視頻、圖片)等。
解析內容
如果是HTML代碼,則可以使用網頁解析器進行解析,如果是Json數據,則可以轉換成Json對象進行解析,如果是二進制的數據,則可以保存到文件做進一步處理。
保存數據
可以保存到本地文件,也可以保存到數據庫(MySQL,Redis,MongoDB等)。

2 爬蟲程序架構及運行流程
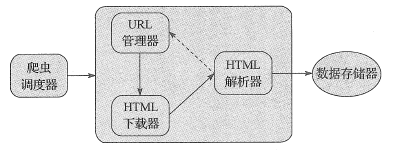
網絡爬蟲程序框架主要包括以下五大模塊:
爬蟲調度器 URL管理器 HTML下載器 HTML解析器 數據存儲器五大模塊功能如下所示:
爬蟲調度器:主要負責統籌其它四個模塊的協調工作。 URL管理器:負責管理URL鏈接,維護已經爬取的URL集合和未爬取的URL集合,提供獲取新URL鏈接的接口。 HTML下載器:用于從URL管理器中獲取未爬取的URL鏈接并下載HTML網頁。 HTML解析器:用于從HTML下載器中獲取已經下載的HTML網頁,并從中解析出新的URL鏈接交給URL管理器,解析出有效數據交給數據存儲器。 數據存儲器:用于將HTML解析器解析出來的數據通過文件或者數據庫的形式存儲起來。網絡爬蟲程序框架的動態運行流程如下所示:
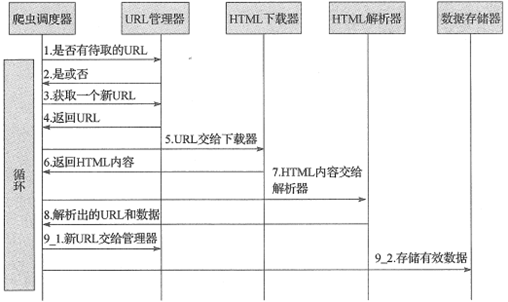
3 小結
本文簡要介紹了Python開發網絡爬蟲的程序框架,將網絡爬蟲運行流程按照具體功能劃分為不同模塊,以便各司其職、協同運作。搭建好網絡爬蟲框架后,能夠有效地提高我們開發網絡爬蟲項目的效率,避免一些重復造車輪的工作。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網。
相關文章:
排行榜

 網公網安備
網公網安備