python 截取XML中bndbox的坐標(biāo)中的圖像,另存為jpg的實(shí)例
文件目錄
Annotations中是XML文件。
JPEGImages中是對(duì)應(yīng)的JPG文件

XML文件
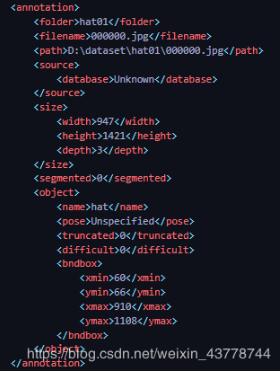
要截取bndbox坐標(biāo)中的內(nèi)容。
python代碼
# -*- coding: utf-8 -*-# @Time : 2020/2/8 22:14# @Author : SanZhi# @File : get_xml.py# @Software: PyCharmimport cv2import numpy as npimport xml.dom.minidomimport osimport argparsedef main(): # JPG文件的地址 img_path = ’D:/ser/JPEGImages/’ # XML文件的地址 anno_path = ’D:/ser/Annotations/’ # 存結(jié)果的文件夾 cut_path = ’D:/ser/cut/’ # 獲取文件夾中的文件 imagelist = os.listdir(img_path) for image in imagelist: image_pre, ext = os.path.splitext(image) img_file = img_path + image img = cv2.imread(img_file) xml_file = anno_path + image_pre + ’.xml’ DOMTree = xml.dom.minidom.parse(xml_file) collection = DOMTree.documentElement objects = collection.getElementsByTagName('object') for object in objects: print('start') bndbox = object.getElementsByTagName(’bndbox’)[0] xmin = bndbox.getElementsByTagName(’xmin’)[0] xmin_data = xmin.childNodes[0].data ymin = bndbox.getElementsByTagName(’ymin’)[0] ymin_data = ymin.childNodes[0].data xmax = bndbox.getElementsByTagName(’xmax’)[0] xmax_data = xmax.childNodes[0].data ymax = bndbox.getElementsByTagName(’ymax’)[0] ymax_data = ymax.childNodes[0].data xmin = int(xmin_data) xmax = int(xmax_data) ymin = int(ymin_data) ymax = int(ymax_data) img_cut = img[ymin:ymax, xmin:xmax, :] cv2.imwrite(cut_path + ’cut_img_{}.jpg’.format(image_pre), img_cut)if __name__ == ’__main__’: main()
補(bǔ)充知識(shí):python讀取XML中bndbox和object name的方法
直接貼代碼了,封裝為了函數(shù),直接調(diào)用即可。其中有幾個(gè)點(diǎn)需要注意。
1、bndbox下面有4個(gè)子對(duì)象,因此不能直接使用firstChild來找到內(nèi)容,需要從該對(duì)象里面繼續(xù)尋找標(biāo)簽為xmin等這樣的對(duì)象,注意要加[0]才正確,有問題的可以直接調(diào)試,然后看變量的結(jié)構(gòu),根據(jù)變量的結(jié)構(gòu)來調(diào)用某一對(duì)象。
2、將空格’ ’替換為’_’,方便命名。但是使用str.replace(’ ’, ’_’)不會(huì)直接改變str的內(nèi)容,返回的字符串是改變后的,因此需要變量保存。
import xml.dom.minidom as xmldomdef get_bndboxfromxml(imageNum, xmlfilebasepath): # 讀取xml文件 bndbox = [0, 0, 0, 0] xmlfilepath = xmlfilebasepath + '%06d' % imageNum+’.xml’ # print(xmlfilepath) domobj = xmldom.parse(xmlfilepath) elementobj = domobj.documentElement sub_element_obj = elementobj.getElementsByTagName(’bndbox’) if sub_element_obj is not None: bndbox[0] = int(sub_element_obj[0].getElementsByTagName(’xmin’)[0].firstChild.data) bndbox[1] = int(sub_element_obj[0].getElementsByTagName(’ymin’)[0].firstChild.data) bndbox[2] = int(sub_element_obj[0].getElementsByTagName(’xmax’)[0].firstChild.data) bndbox[3] = int(sub_element_obj[0].getElementsByTagName(’ymax’)[0].firstChild.data) return bndboxdef get_bndboxnamefromxml(imageNum, xmlfilebasepath): bndbox = [0, 0, 0, 0] xmlfilepath = xmlfilebasepath + '%06d' % imageNum + ’.xml’ domobj = xmldom.parse(xmlfilepath) elementobj = domobj.documentElement sub_element_obj = elementobj.getElementsByTagName(’name’) name = sub_element_obj[0].firstChild.data.replace(’ ’, ’_’) return name
以上這篇python 截取XML中bndbox的坐標(biāo)中的圖像,另存為jpg的實(shí)例就是小編分享給大家的全部?jī)?nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備