python 判斷txt每行內(nèi)容中是否包含子串并重新寫入保存的實例
假設(shè)需要批量處理多個txt文件,然后將包含子串的內(nèi)容寫入一個txt文件中,這里假設(shè)我的子串為'_9'和“_10”
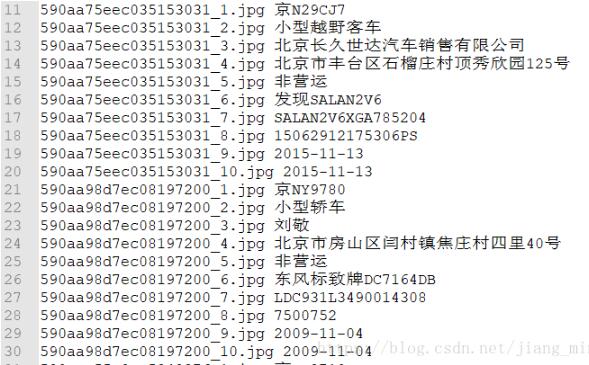
下面就是我想要得到的其中兩行內(nèi)容(實際上還有很多行哈哈):
直接上代碼:
#! /usr/bin/python# -*- coding:UTF-8 -*- import osimport os.pathimport string
txt文件所在的路徑和需要保存的目標路徑(根據(jù)自己的實際目錄進行更改即可):
Crop-Ocr_txt文件夾內(nèi)放置了我需要批量處理的所有txt,我在同級目錄下新建一個文件夾名為1000_simple_Ocrtxts,這里目標路徑隨意就好,能方便找到就行
txt_path = ’D:/youxinProjections/trafic-youxin/MobileNet_v1/obtain_qq_json_new/Crop_Ocr_txt/’des_txt_path = ’D:/youxinProjections/trafic-youxin/MobileNet_v1/obtain_qq_json_new/1000_simple_OCRtxts/’ txt_files = os.listdir(txt_path) #txt_files能得到該目錄下的所有txt文件的文件名
定義一個函數(shù)專門用來取包含子串的內(nèi)容并寫入到新的txt文件中,在后邊的主函數(shù)中直接調(diào)用這個函數(shù)就行就行:
def select_simples(): for txtfile in txt_files: if not os.path.isdir(txtfile): in_file = open(txt_path + txtfile, ’r’) out_file = open(des_txt_path + txtfile, ’a’) # 此處自動新建一個文件夾和txtfile的文件名相同,’a’為自動換行寫入 lines = in_file.readlines() for line in lines:str_name = line.split(' ')[0] # 這里獲取的是txt文件中每行內(nèi)容以空格隔開的第一個元素,也就是我自己txt文件中的*.jpg那一塊內(nèi)容
str1 = ’_9’ # 這就是我要判斷的子串str2 = ’_10’ # 這也是子串 #if (string.find(str_name, str1)!=-1) or (string.find(str_name, str2)):if (str1 in str_name) or (str2 in str_name): # in 可以判斷在str_name中是否包含有兩個子串, out_file.write(line) # 若包含子串,則將該行內(nèi)容全部重新寫入新的txt文件 print(str_name) out_file.close()
主函數(shù)到了!:
if __name__ == ’__main__’:select_simples()
曬一下最后的結(jié)果:
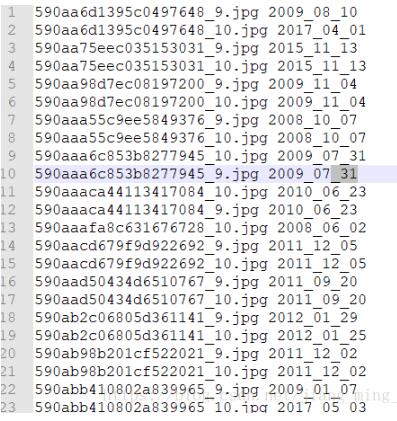
完美有沒有!!!
補充知識:python判斷文件中有否重復行,逐行讀文件檢測另一文件中是否存在所讀內(nèi)容
我就廢話不多說了,還是直接看代碼吧!
#!/bin/env python# coding:utf-8#程序功能是為了完成判斷文件中是否有重復句子#并將重復句子打印出來res_list = []f = open(’./downloadmd5.txt’,’r’)res_dup = []index = 0file_dul = open(’./r_d.txt’, ’w’)file_last = open(’./r_nd.txt’,’w’)for line in f.readlines(): index = index + 1 if line in res_list: temp_str = '' #temp_str = temp_str + str(index) + ’,’ #要變?yōu)閟tr才行 temp_line = ’’.join(line) temp_str = temp_str+temp_line #最終要變?yōu)閟tr類型 file_dul.write(temp_str); #將重復的存入到文件中 else: res_list.append(line) file_last.write(line)
#!/bin/env python# coding:utf-8import reres_list = []f = open(’./md5.txt’,’r’)f2 = open(’./virus.conf’,’r’)index = 0#沒重復的文件名file_dul = open(’./m_nd.txt’, ’w’)#重復的文件名file_ex = open(’./m_d.txt’, ’w’)virstr = f2.read();for line in f.readlines(): line=line.strip(’n’) if(re.search(line, virstr)): line = line + ’n’ file_ex.write(line); #調(diào)用刪除rm -rf filename else: line = line+’n’ file_dul.write(line);
以上這篇python 判斷txt每行內(nèi)容中是否包含子串并重新寫入保存的實例就是小編分享給大家的全部內(nèi)容了,希望能給大家一個參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. 解決Android Studio Design界面不顯示layout控件的問題2. python mysql 字段與關(guān)鍵字沖突的解決方式3. bootstrap select2 動態(tài)從后臺Ajax動態(tài)獲取數(shù)據(jù)的代碼4. Python加載數(shù)據(jù)的5種不同方式(收藏)5. python讀取中文路徑時出錯(2種解決方案)6. Python用K-means聚類算法進行客戶分群的實現(xiàn)7. python編寫五子棋游戲8. Java源碼解析之接口List9. Java xml數(shù)據(jù)格式返回實現(xiàn)操作10. layui Ajax請求給下拉框賦值的實例

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備