Python腳本實現(xiàn)Zabbix多行日志監(jiān)控過程解析
通過使用zabbix 日志監(jiān)控 我發(fā)現(xiàn)一個問題 例如oracle的日志有報錯的情況 ,通常不會去手動清理 這樣的話當(dāng)?shù)诙斡腥罩緦戇M(jìn)來的時候 zabbix的機(jī)制是回去檢查全部日志,這樣的話之前已經(jīng)告警過的錯誤日志,又會被檢查到,這樣就會出現(xiàn)重復(fù)告警,而且zabbix的日志監(jiān)控只能讀到匹配當(dāng)前行關(guān)鍵字的數(shù)據(jù),感覺不太靈活, 比如我想要匹配到的關(guān)鍵字之后再當(dāng)前關(guān)鍵字的下N行再去匹配另一個關(guān)鍵字這個時候就比較麻煩,在這里給大家推薦一個有效,便捷解決的方式。
通過Python腳本實現(xiàn)日志監(jiān)控 要求 1 記錄腳本檢查日志位置,避免下次觸發(fā)腳本的時候出現(xiàn)重復(fù)告警 2 關(guān)鍵字匹配支持正則 3 支持多個關(guān)鍵字查詢,例如第一個關(guān)鍵字匹配到當(dāng)之后在這個關(guān)鍵字的下N行再去匹配第二個關(guān)鍵字 具體傳參格式python3 npar.py /u03/z.txt ’(ORA-|REEOR),(04030|02011)’ 2
第一個參數(shù)是日志路徑 第二個參數(shù)是關(guān)鍵字 第三個參數(shù)為 匹配到第一個表達(dá)式這種的關(guān)鍵字后再去地 N(2)行去匹配第二個關(guān)鍵詞(04030|02011)具體腳本實現(xiàn)如下
import osimport syslogtxt = 'logtxt.txt'def read_txt(files, start_line):data = []data.append('')with open(str(files) + '', 'r',encoding = ’UTF-8’) as f:for line in f.readlines():line = line.strip(’n’)# 去掉列表中每一個元素的換行符data.append(line)# 記錄本次的行數(shù)wirte_log(len(data) - 1)if len(data) > start_line:return data[start_line - 1: ]else :print('開始行數(shù)大于文本文件總行數(shù)!')def wirte_log(lines):global logtxtwith open(logtxt, 'w') as file: #”w '代表著每次運行都覆蓋內(nèi)容file.write(str(lines))def read_log():global logtxtif not os.path.exists(logtxt):with open(logtxt, 'w') as file: #”w '代表著每次運行都覆蓋內(nèi)容file.write(str(1))with open(logtxt + '', 'r', encoding =’UTF-8’) as f:s_lines = f.readlines()print('從第' + str(s_lines[0]) + '行開始')return s_lines[0]def deal_read_log(files, keyword,interval_line):keywords = keyword.replace('(', '').replace(')', '').replace('’', '').replace(’'’,’'’).split(’,’)start_keywords = keywords[0].split('|')end_keywords = keywords[1].split('|')start_line = read_log()lines_data = read_txt(files, int(start_line))for_line = 1while (for_line < len(lines_data)):#print(for_line)# print(lines_data[for_line])#if end_keywords in lines_data[for_line]:#print(lines_data[for_line])# print('-------------------')# for_line = for_line + 1#else :isexist = 0for sk in start_keywords:if sk in lines_data[for_line]:isexist = 1break;if isexist == 1:#if start_keywords[0] in lines_data[for_line] or start_keywords[1] inlines_data[for_line]:#當(dāng)前行有end_keywordsisexist2 = 0for sk in end_keywords:if sk in lines_data[for_line]:isexist2 = 1break;if isexist2 == 1:#print('行數(shù)=' + str(start_line - 1 +for_line) + '-' + str(start_line - 1 +for_line))print(lines_data[for_line])else :#當(dāng)前行沒有end_keywords。 往下interval_line行去尋找# 標(biāo)記當(dāng)前行數(shù)flag_line = for_linecount = 1for_line = for_line + 1while (for_line < len(lines_data)):isexist3 = 0for sk in end_keywords:if sk in lines_data[for_line]:isexist3 = 1break;if isexist3 == 1:#print('行數(shù)=' + str(start_line - 1 +flag_line) + '-' + str(start_line -1 + for_line))for prin in range(flag_line, for_line +1):print(lines_data[prin])break;for_line = for_line + 1if count == int(interval_line):break;count = count + 1for_line = for_line - 1for_line = for_line + 1if name == ’main’:files = sys.argv[1]if ’.log’ in files:logtxt = files.replace('.log','_log.txt')else :logtxt = files.replace('.txt','_log.txt')# files = 'ora.txt'keywords = sys.argv[2]# keywords = '’((04030|04000),ORA-)’'#上下關(guān)聯(lián)行數(shù)interval_line = int(sys.argv[3])# interval_line = 10deal_read_log(files, keywords,interval_line)
接下來就是添加監(jiān)控了
在agent的conf 文件里面添加UserParameter

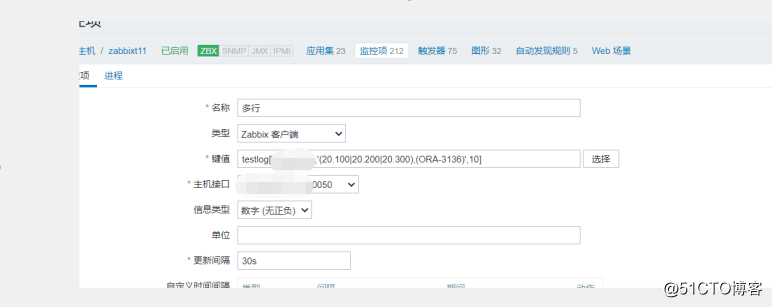
到這里監(jiān)控就完成了
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. moment轉(zhuǎn)化時間戳出現(xiàn)Invalid Date的問題及解決2. python爬蟲實戰(zhàn)之制作屬于自己的一個IP代理模塊3. Python中內(nèi)建模塊collections如何使用4. 關(guān)于WPF WriteableBitmap類直接操作像素點的問題5. UDDI FAQs6. 使用JSP技術(shù)實現(xiàn)一個簡單的在線測試系統(tǒng)的實例詳解7. Python中matplotlib如何改變畫圖的字體8. python實現(xiàn)坦克大戰(zhàn)9. 開發(fā)效率翻倍的Web API使用技巧10. 跟我學(xué)XSL(一)第1/5頁

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備