Python文件名匹配與文件復制的實現
文件名的匹配,實際上就是相當于獲取文件名(不含后綴),然后利用獲取到的文件名到另外一個文件夾中去尋找對應的文件,然后將文件取出,放置到指定文件夾下.概括的來說,分三個步驟:一是取出遍歷目錄A,得到各個文件文件名;二是利用該文件名,與指定路徑B拼接,并加上后綴,產生目標文件名;三是根據拼接產生的目標文件名,將相應文件復制到指定目錄C.
好,那么我們開始寫代碼吧~~~
step1:獲取指定目錄A下面的所有文件名.不包含文件后綴.主要基于以下思想:
def GetFileNameAndExt(filename): import os (filepath,tempfilename) = os.path.split(filename); (shotname,extension) = os.path.splitext(tempfilename); return shotname,extension
測試代碼
print(GetFileNameAndExt(’c:jb51index.html’))
返回結果:
(’index’, ’.html’)
實際代碼如下
#coding=utf-8import osimport os.pathdef GetFileNameAndExt(filename): (filepath,tempfilename) = os.path.split(filename); (shotname,extension) = os.path.splitext(tempfilename); return shotname,extension source_dir=’/home/nvidia/xmlReader/circle’label_dir=’/home/nvidia/xmlReader/label’annotion_dir=’/home/nvidia/xmlReader/annocation’ ##1.將指定A目錄下的文件名取出,并將文件名文本和文件后綴拆分出來img=os.listdir(source_dir) #得到文件夾下所有文件名稱s=[]for fileNum in img: #遍歷文件夾 if not os.path.isdir(fileNum): #判斷是否是文件夾,不是文件夾才打開 print fileNum #打印出文件名 imgname= os.path.join(source_dir,fileNum) print imgname #打印出文件路徑 (imgpath,tempimgname) = os.path.split(imgname); #將路徑與文件名分開 (shotname,extension) = os.path.splitext(tempimgname); #將文件名文本與文件后綴分開 print shotname,extension print ’~~~~’
step2:二是利用該文件名,與指定路徑B拼接,并加上后綴,產生目標文件名
##2.將取出來的文件名文本與特定后綴拼接,在于路徑拼接,得到B目錄下的文件 xmlname=os.path.join(label_dir,shotname,’.xml’) print xmlname
但是得到的輸出是有分隔符的.
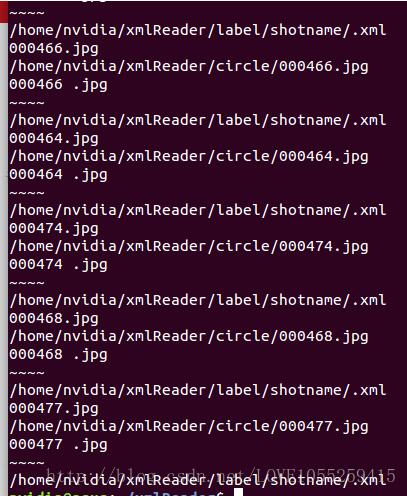
如何去掉分隔符呢?或者說如何拼接文件名文本和后綴呢? 基于以下Python基礎
’%d.txt’%fname
這樣基本上可以表示比如120.txt這樣的字符串了。
代碼如下:
##2.將取出來的文件名文本與特定后綴拼接,在于路徑拼接,得到B目錄下的文件 tempxmlname=’%s.xml’%shotname xmlname=os.path.join(label_dir,tempxmlname) print xmlname
我們來看看輸出:
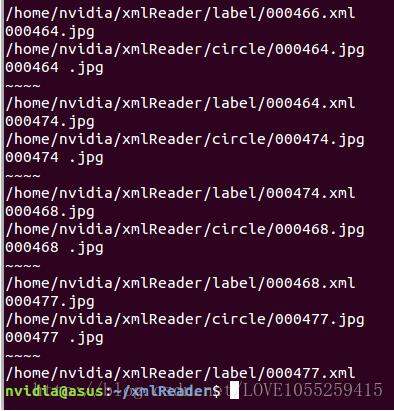
大功告成,現在我們得到了想要的數據格式,開始到這個指定的路徑去尋找文件匹配文件名了~~~~
step3:定位到目標文件名,將其復制到指定目錄下,保持文件名不變.(Python文件復制)
##3.根據得到的xml文件名,將對應文件拷貝到指定目錄C
shutil.copy(xmlname,annotion_dir)
這樣,與圖片相關的標注文件就全部拷貝過來了~~~
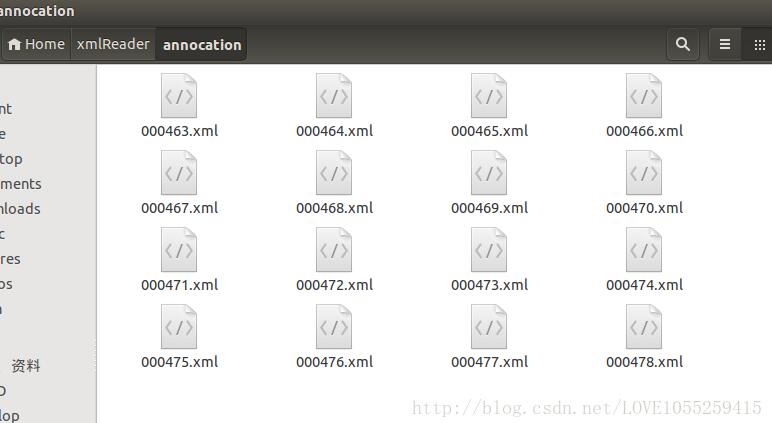
最后,我們來看看我們最終的代碼:
#coding=utf-8import osimport os.pathimport shutil #Python文件復制相應模塊 def GetFileNameAndExt(filename): (filepath,tempfilename) = os.path.split(filename); (shotname,extension) = os.path.splitext(tempfilename); return shotname,extension source_dir=’/home/nvidia/xmlReader/circle’label_dir=’/home/nvidia/xmlReader/label’annotion_dir=’/home/nvidia/xmlReader/annocation’ ##1.將指定A目錄下的文件名取出,并將文件名文本和文件后綴拆分出來img=os.listdir(source_dir) #得到文件夾下所有文件名稱s=[]for fileNum in img: #遍歷文件夾 if not os.path.isdir(fileNum): #判斷是否是文件夾,不是文件夾才打開 print fileNum #打印出文件名 imgname= os.path.join(source_dir,fileNum) print imgname #打印出文件路徑 (imgpath,tempimgname) = os.path.split(imgname); #將路徑與文件名分開 (shotname,extension) = os.path.splitext(tempimgname); #將文件名文本與文件后綴分開 print shotname,extension print ’~~~~’##2.將取出來的文件名文本與特定后綴拼接,再與路徑B拼接,得到B目錄下的文件 tempxmlname=’%s.xml’%shotname xmlname=os.path.join(label_dir,tempxmlname) print xmlname##3.根據得到的xml文件名,將對應文件拷貝到指定目錄C shutil.copy(xmlname,annotion_dir)
至此,大功告成!
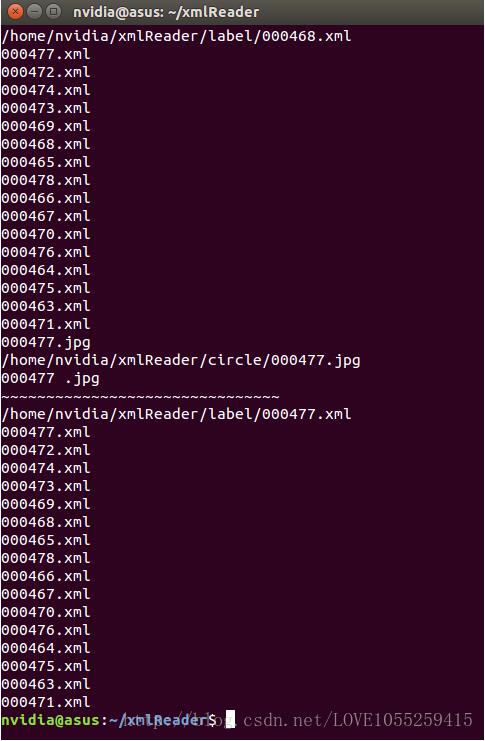
以上這篇Python文件名匹配與文件復制的實現就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持好吧啦網。
相關文章:

 網公網安備
網公網安備