文章詳情頁
python - 標簽樹的下行遍歷如何跳過第一個標簽
瀏覽:118日期:2022-08-08 11:07:17
問題描述
爬取網頁用下行遍歷的找出了我要的標簽,但第一個的內容我是不要的用.children好像無法跳出第一個標簽
for tr in soup.find(id='endText').children: if tr.string is not None:a = tr.string
網頁的內容:
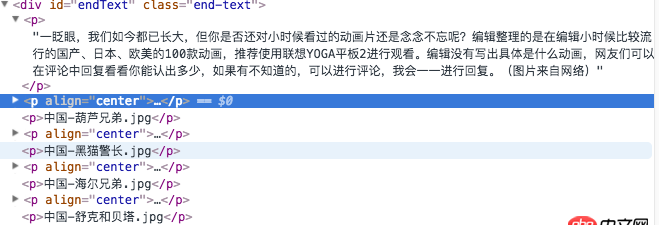 原鏈接:http://digi.163.com/14/1115/0...
原鏈接:http://digi.163.com/14/1115/0...
問題解答
回答1:p_list = list(soup.find(id='endText').find_all(’p’))for p in p_list[1:]: text = p.get_text() img = p.find('img') if img:print img.get(’src’) if text:print text
相關文章:
1. Span標簽2. css - 求推薦適用于vue2的框架 像bootstrap這種類型的3. 關docker hub上有些鏡像的tag被標記““This image has vulnerabilities””4. docker-machine添加一個已有的docker主機問題5. docker images顯示的鏡像過多,狗眼被亮瞎了,怎么辦?6. mysql - msyql 判斷字段不為空 簡單方法7. angular.js使用$resource服務把數據存入mongodb的問題。8. dockerfile - [docker build image失敗- npm install]9. redis啟動有問題?10. css - 關于div自適應問題,大家看圖吧,說不清
排行榜

 網公網安備
網公網安備