crawler - 如何在 Python 爬蟲中完成 JavaScript 函數(shù)翻頁?
問題描述
本人爬取一個網(wǎng)頁時注意到它的翻頁時靠這樣的一個函數(shù)實現(xiàn)的, 翻頁之后頁面網(wǎng)址也不變:
<input name='goto2' onclick='dirGroupMblogToPage(document.getElementById(’dirGroupMblogcp2’).value)' type='button' value='Go'/> </input> function dirGroupMblogToPage(currentPage){ jQuery.post('dirGroupMblog.action', {'page.currentPage':currentPage,gid:MI.TalkBox.gid}, function(data){$('#talkMain').html(data);window.scrollTo(0, $css.getY(MI.talkList._body)-65); });}
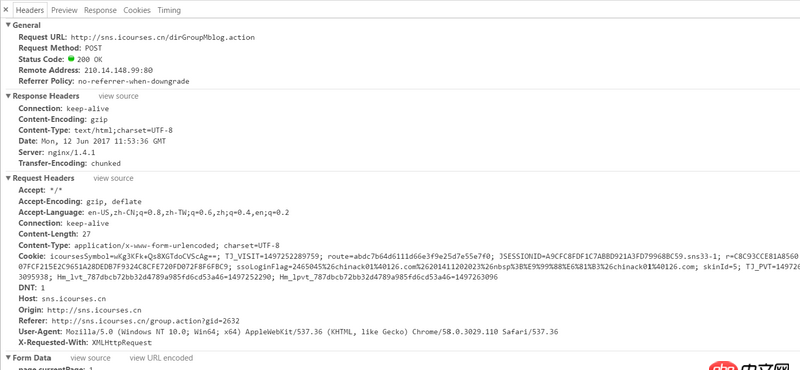
寫了這樣的函數(shù)試圖實現(xiàn)翻頁:
def login_page(login_url, content_url, usr_name='******@126.com', passwd='******'): # 實現(xiàn)登錄, 返回Session對象和獲得的頁面 post_data = {’r’: ’on’, ’u’: usr_name, ’p’: passwd} s = requests.Session() s.post(login_url, post_data) r = s.get(content_url) return s, rdef turn_page(s, next_page, content_url): post_url = 'http://sns.icourses.cn/dirGroupMblog.action' post_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36','X-Requested-With':'XMLHttpRequest'} post_data = {'page.currentPage': next_page, 'gid': 2632} s.post(post_url, data=post_data, headers = post_headers) res = s.get(content_url) return res
但是調(diào)用turn_page()之后沒能實現(xiàn)翻頁。請問應該怎么解決這個問題? 另外請問想要解決好這類問題需要自學哪些方面的知識呢?謝謝!
問題解答
回答1:推薦使用 selenium
例如,如果需要點擊界面上,下一頁的按鈕,或者說需要輸入上下左右鍵,頁面可以翻頁,selenium webdriver可以做到,給出一個參考(我以前用來爬起點中文網(wǎng)的小說)
selenium 可以與頁面進行交互,單擊,雙擊,輸入,等待頁面加載(隱式等待,和顯式等待)。。。。
from selenium import webdriver# from selenium.webdriver.common.keys import Keys#driver = webdriver.PhantomJS(executable_path='D:phantomjs-2.1.1-windowsbinphantomjs')# 我的windows 已配置環(huán)境變量,不需指定 executable_path,使用 Chrome需要對應的瀏覽器以及驅(qū)動程序driver = webdriver.Chrome()# url 為你需要加載的頁面urlurl = ’http://sns.icourses.cn/*****’# 打開頁面driver.get(url)# 在你的例子中,是需要點擊 button ,通過class 屬性獲取到button,然后執(zhí)行單擊 .click()# 如果需要準確定位,可以自行搜索其他的 find_driver.find_element_by_class_name('buttonJump').click()# selenium webdriver 還有很多其它高級的用法,自行谷歌,你這個問題,搜索應該是能得到答案的,回答2:
分幾種情況,1、頁面上通過 js 效果實現(xiàn)滑動或者點擊實現(xiàn)翻頁;2、頁面上通過超鏈接點擊實現(xiàn)翻頁;
可以通過 chrome 的開發(fā)者工具中的 network 分析得到結(jié)果反會的是 html 頁面還是反饋 json 渲染。json 的話就好辦了,直接拿結(jié)果。普通html 頁面需要使用正則匹配到換頁。然后將鏈接放入待爬的池子中。
/a/11...
相關(guān)文章:
1. python 利用subprocess庫調(diào)用mplayer時發(fā)生錯誤2. python文檔怎么查看?3. python - Pycharm的Debug用不了4. javascript - 關(guān)于apply()與call()的問題5. datetime - Python如何獲取當前時間6. javascript - nginx反向代理靜態(tài)資源403錯誤?7. html - eclipse 標簽錯誤8. 請問PHPstudy中的數(shù)據(jù)庫如何創(chuàng)建索引9. 安全性測試 - nodejs中如何防m(xù)ySQL注入10. python - pycharm 自動刪除行尾空格
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備