python - 用scrapy爬取網站內容時,如何忽略某些內容為空的值;
問題描述
我爬取京東上所有手機信息時會碰到如下問題:1、返回值過多,如下圖片所示: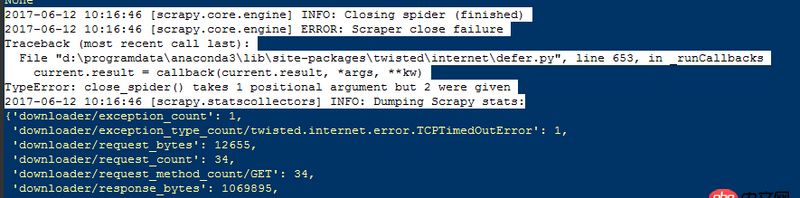
2、spider代碼如下:
-- coding: utf-8 --import scrapyfrom scrapy.http import Requestfrom ueinfo.items import UeinfoItem
class MrueSpider(scrapy.Spider):
name = ’mrue’allowed_domains = [’jd.com’]start_urls = [’http://jd.com/’]def parse(self, response): key='手機' for i in range(1,2):url='https://search.jd.com/Search?keyword='+str(key)+'&enc=utf-8&page='+str((i*2)-1)#print(url)yield Request(url=url,callback=self.page)def page(self,response): #body=response.body.decode('utf-8','ignore') allid=response.xpath('//p[@class=’p-focus’]//a/@data-sku').extract() for j in range(0,len(allid)):thisid=allid[j]url1='https://item.jd.com/'+str(thisid)+'.html'#print(url1)yield Request(url=url1,callback=self.next)def next(self,response): item=UeinfoItem() item['pinpai']=response.xpath('//ul[@id=’parameter-brand’]/li/@title').extract() #print(item['pinpai']) item['xinghao']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’型號’]/following::*[1]').extract() #print(item['xinghao']) item['nianfen']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’上市年份’]/following::*[1]').extract() #print(item['nianfen']) item['yuefen']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’上市月份’]/following::*[1]').extract() #print(item['yuefen']) item['caozuoxt']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’操作系統’]/following::*[1]').extract() #print(item['caozuoxt']) item['cpupp']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’CPU品牌’]/following::*[1]').extract() #print(item['cpupp']) item['cpuhs']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’CPU核數’]/following::*[1]').extract() #print(item['cpuhs']) item['cpuxh']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’CPU型號’]/following::*[1]').extract() #print(item['cpuxh']) item['shuangkalx']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’雙卡機類型’]/following::*[1]').extract() #print(item['shuangkalx']) item['mfnetwangl']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’4G網絡’]/following::*[1]').extract() #print(item['mfnetwangl']) item['fnetwangl']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’網絡頻率(4G)’]/following::*[1]').extract() #print(item['fnetwangl']) item['netwanglplus']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’指紋識別’]/following::*[1]').extract() #print(item['netwanglplus']) item['volte']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’高清語音通話(VOLTE)’]/following::*[1]').extract() #print(item['volte']) item['screenstyle']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’主屏幕尺寸(英寸)’]/following::*[1]').extract() #print(item['screenstyle']) item['fenbiel']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’分辨率’]/following::*[1]').extract() #print(item['fenbiel']) item['dianchirl']=response.xpath('//p[@class=’Ptable’]//p[@class=’Ptable-item’]//dl//dt[text()=’電池容量(mAh)’]/following::*[1]').extract() #print(item['dianchirl']) yield item
pipelines的代碼如下:
-- coding: utf-8 --import pymysql
class UeinfoPipeline(object):
def __init__(self): self.conn=pymysql.connect(host='127.0.0.1',user='root',passwd='root',db='mysql')def process_item(self, item, spider): try:pinpai=item['pinpai'][0]xinghao=item['xinghao'][0]nianfen=item['nianfen'][0]yuefen=item['yuefen'][0]caozuoxt=item['caozuoxt'][0]coupp=item['cpupp'][0]cpuhs=item['cpuhs'][0]cpuxh=item['cpuxh'][0]shuangkalx=item['shuangkalx'][0]mfnetwangl=item['mfnetwangl'][0]fnetwangl = item['fnetwangl'][0]netwanglplus=item['netwanglplus'][0]volte=item['volte'][0]screenstyle=item['screenstyle'][0]fenbiel=item['fenbiel'][0]dianchirl=item['dianchirl'][0]sql='insert into uems(pinpai,xinghao,nianfen,yuefen,caozuoxt,cpupp,cpuhs,cpuxh,shuangkalx,mwangluo,fwangluo,wangluoplus,volte,screenstyle,fenbian,dianchi)VALUES(’'+pinpai+'’,’'+xinghao+'’,’'+nianfen+'’,’'+yuefen+'’,’'+caozuoxt+'’,’'+coupp+'’,’'+cpuhs+'’,’'+cpuxh+'’,’'+shuangkalx+'’,’'+mfnetwangl+'’,’'+fnetwangl+'’,’'+netwanglplus+'’,’'+volte+'’,’'+screenstyle+'’,’'+fenbiel+'’,’'+dianchirl+'’)'self.conn.query(sql)#print(mfnetwangl)return item except Exception as err:passdef close_spider(self): self.conn.close()
問題解答
回答1:pipelines中的
def close方法定義錯誤了
應為這樣
def close(self, spider)
至于忽略某些內容為空的值用for 可能節省代碼!
def process_item(self, item, spider): for k,v in item.items():if v == ’’: raise DropItem(repr(item))
 網公網安備
網公網安備