網(wǎng)頁爬蟲 - python 爬蟲怎么處理json內(nèi)容
問題描述
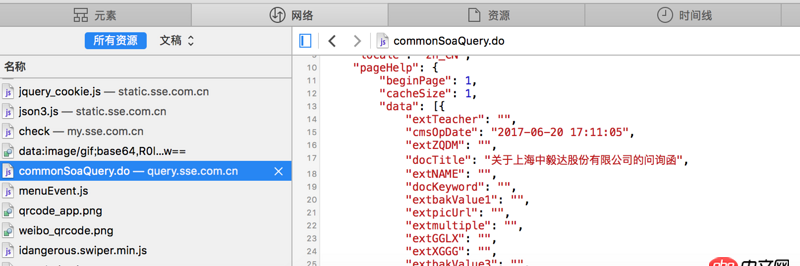
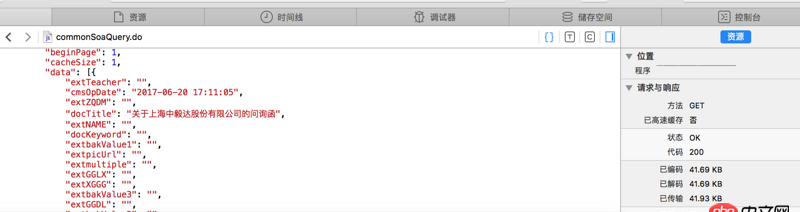
看不清的話 網(wǎng)站地址是http://www.sse.com.cn/disclos...紅字是我需要的內(nèi)容 但是我提取不出來求教怎么操作
問題解答
回答1:import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5’headers = { ’Referer’:’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’:’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36’}r = requests.get(url, headers=headers)print r.json()[’result’]回答2:
import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5&_=1498029409382’session = requests.session()session.headers.update({ ’Referer’: ’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’: ’Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36’})result = session.get(url).json()print result
相關(guān)文章:
1. javascript - 關(guān)于apply()與call()的問題2. javascript - 有適合開發(fā)手機(jī)端Html5網(wǎng)頁小游戲的前端框架嗎?3. python - pandas按照列A和列B分組,將列C求平均數(shù),怎樣才能生成一個列A,B,C的dataframe4. python - Pycharm的Debug用不了5. html - eclipse 標(biāo)簽錯誤6. python 利用subprocess庫調(diào)用mplayer時發(fā)生錯誤7. javascript - nginx反向代理靜態(tài)資源403錯誤?8. python文檔怎么查看?9. python - pycharm 自動刪除行尾空格10. 安全性測試 - nodejs中如何防m(xù)ySQL注入
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備